
はじめに
Power Automate や Logic Apps には 標準で Azure Cognitive Service の中の Computer Vision API が利用可能です。
特に、画像やPDFドキュメントからの文字起こしができる "Optical Character Recognition (OCR) to JSON/Text" は使ったことがある方も多いのではないでしょうか。
使ってみるとわかるのですが、この OCR API、実行こそ早いものの日本語に対する読み取り精度はイマイチです。

そんな中、同 Computer Vision の Read API (v3.2) が日本語への精度が高いという記事を見ましたので、Power Automateでも試してみました。
Computer Vision のリソース作成などについては上の記事に書いてありますので、ここでは Power Automate でどう利用するかに絞っていきます。
なお、この API を Power Automate で利用する場合には プレミアムな HTTP アクションが必要になります。
どのくらいイマイチか
先に結果を見ていただければ、違いは一目瞭然。
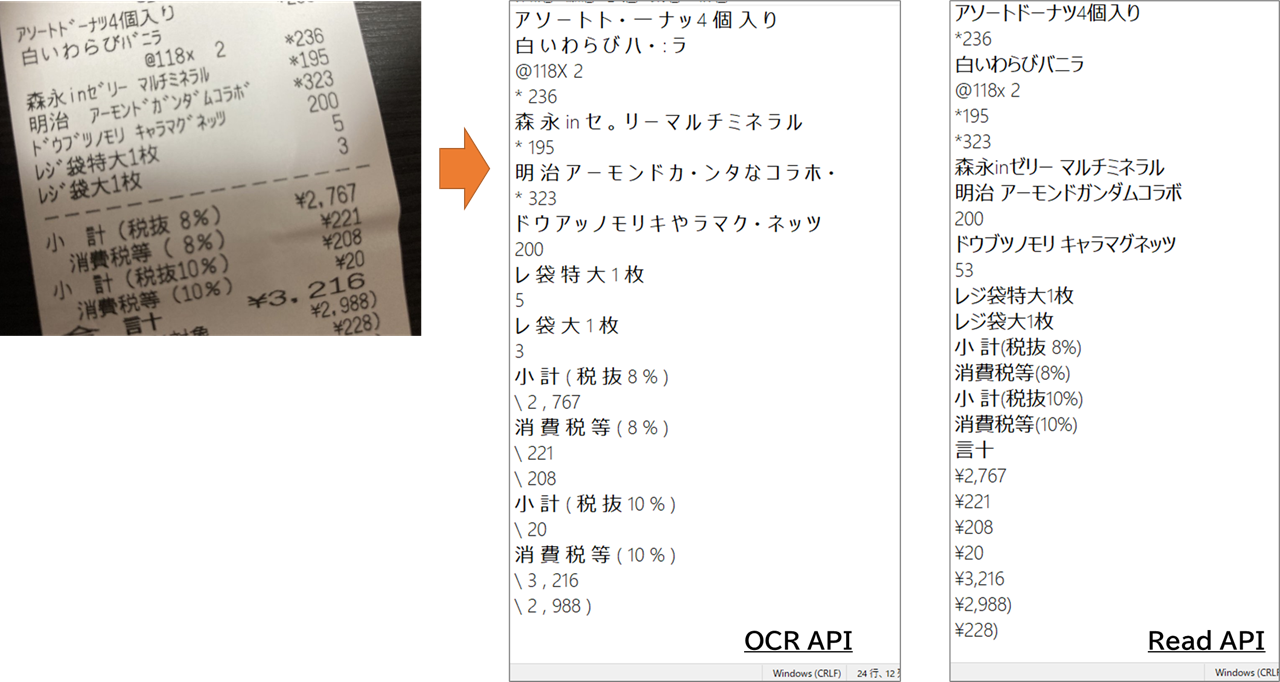
レシートを読み取った結果です。 OCR APIでは特に半角カタカナが厳しいですね。あとはすべての文字の間に半角スペースが入っています。
1つのテキストとして認識しているわけではなくて、文字を読み取っているかたちです。
一方 Read APIでは、意味のある単位で文字が読み取られていることがわかります。半角カタカナもばっちり。
これで 『Read API、使ってみようかな?』となっていただけたのではないかと。
Automate での利用 (HTTPアクション)
Power Automate / Logic Apps で Read API を使う方法はとても簡単です。
ただ、OCR API と違い、処理結果がすぐに返ってくるタイプではないので、[Read API] → [Read Result API] と2段階にする必要があります。

実際に、フローを作るときには、Read API 実行~ Read Result API の間で 適当な長さの Delay を入れています。即時 Read Result API を実行しても "解析中だよ!" と返されるので気を付けてください。
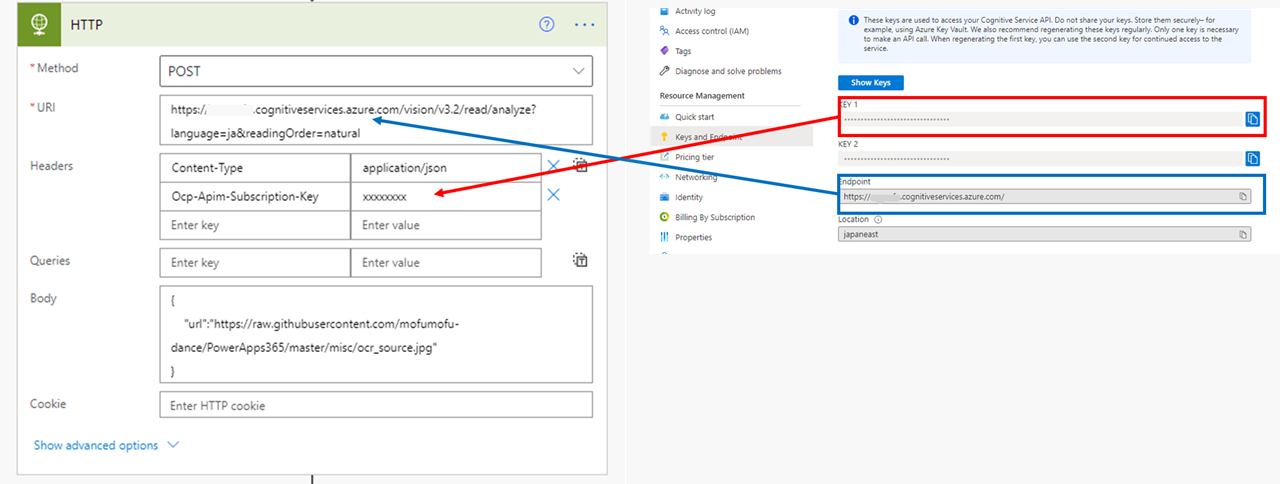
Read API は ファイルそのもの (Binary) と 画像URL を入力にすることができます。 それぞれのケースでヘッダーとボディをどう設定するのか見ていきます。
URLの場合
入力を画像URLにする場合、かならず匿名アクセス可能なものを指定してください。
設定は以下の通りです。
URL
https://{endpoint}/vision/v3.2/read/analyze?language=ja&readingOrder=natural
Headers
| キー | 値 |
|---|---|
| Content-Type | application/json |
| Ocp-Apim-Subscription-Key | {作成したリソースのKey} |
Body
{ "url":"ここに画像URL" }
これだけです。
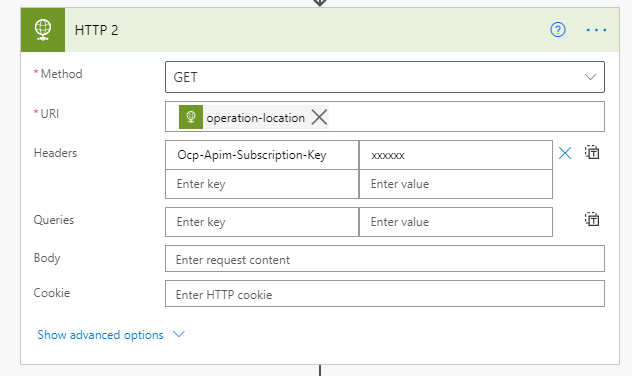
読み取り結果を取得する処理は、URL・画像ファイル共通で以下の通りです。
URL
@{outputs('HTTP')['headers']?['operation-location']}
Headers
| キー | 値 |
|---|---|
| Ocp-Apim-Subscription-Key | {作成したリソースのKey} |
結果の取得は GET です。URLには、最初の Read API を実行したアクションの出力にあるヘッダーから、"operation-location" という項目を読み取って設定してください。
画像ファイル の場合
画像ファイルと言いながら PDF でもOKです。 (Supported image formats: JPEG, PNG, BMP, PDF and TIFF)
URL
https://{endpoint}/vision/v3.2/read/analyze?language=ja&readingOrder=natural
Headers
| キー | 値 |
|---|---|
| Content-Type | application/octet-stream |
| Ocp-Apim-Subscription-Key | {作成したリソースのKey} |
Body
{ "$content-type":"image/jpeg", "$content":"/9j/4AAQSkZJRgABAQEAYABgAAD/2wBDAAMCAgMCB....(読み取るファイルのbase64文字列)" }
URLの場合との違いは、ヘッダーにある "Content-Type" と、 ボディの形式です。
ボディはメディアの種類とbase64文字列で構成されています。 Power Automate にある たいていのファイル取得アクションでは、この形式そのもので、あるいは "$content" 部分のみ取得できるので、適宜加筆してください。
とにかく大事なのは {"$content-type":"xxx", "$content":"xxxxx"} の形式になっていることです!

読み取り結果取得は先ほどと同様なので割愛します。
小ネタ
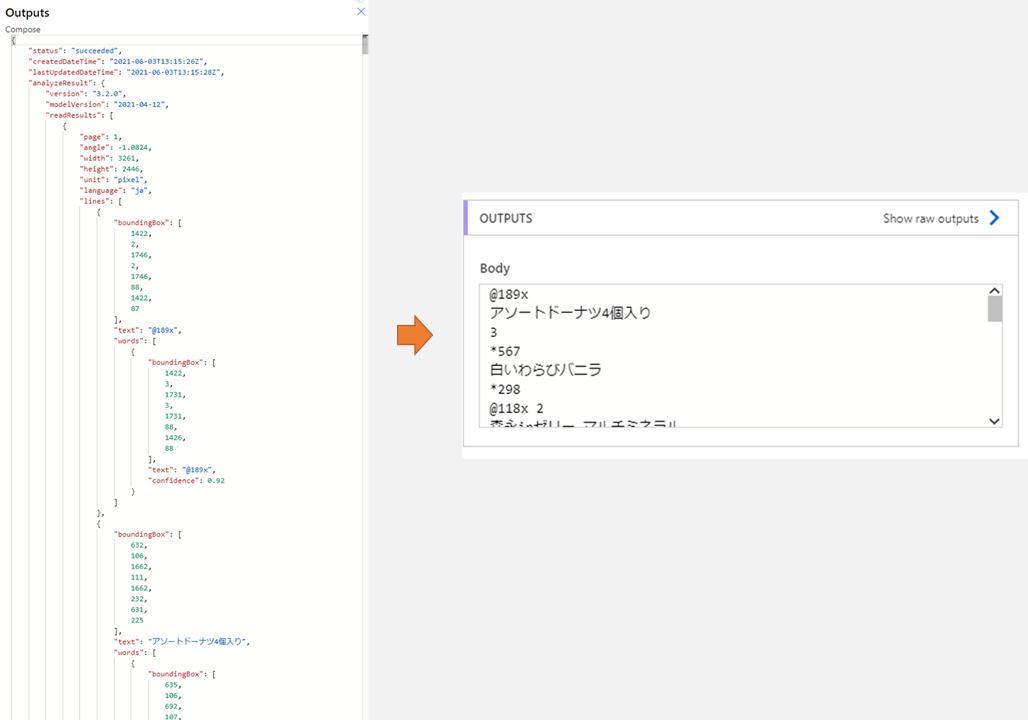
読み取り結果取得の Read Result API では、読み取ったテキストだけでなく座標も返されます。JSONも結構複雑です。
{ "status": "succeeded", "createdDateTime": "2020-09-21T15:27:53Z", "lastUpdatedDateTime": "2020-09-21T15:27:55Z", "analyzeResult": { "version": "3.1.0", "modelVersion": "2021-04-12", "readResults": [ { "page": 1, "angle": 12.8345, "width": 1254, "height": 704, "unit": "pixel", "lines": [ { "boundingBox": [ 145, 0, 1236, 215, 1225, 272, 134, 55 ], "text": "Nutrition Facts Amount Per Serving", "appearance": { "style": "print", "styleConfidence": 1.0 }, "words": [ { "boundingBox": [ 144, 0, 460, 57, 450, 112, 135, 57 ], "text": "Nutrition", "confidence": 0.981 }, ...
もしこの結果から、テキストだけ抜き出したいなと思ったときには以下のようなアクションが使えます。
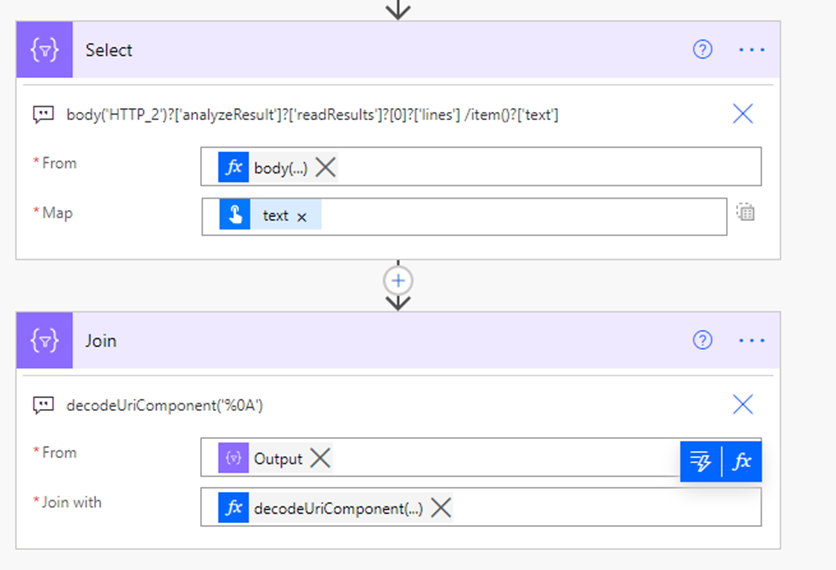
まずは Select (選択) アクションで テキストのみの配列を作ります。
From には body('HTTP_2')?['analyzeResult']?['readResults']?[0]?['lines'] を入れています。※HTTP 2 は Read Result API を実行したアクション名
Map には item()?['text'] これだけです。
あとは Join (結合) アクションで Select の結果を decodeUriComponent('%0A') (改行コード) で結合しています。
こうすると、先ほどの難解なJSONから、読み取った文字列を改行で並べただけの文字列ができます。
※ただしここでは読み取ったドキュメントが1ページであることを前提にしています。複数ページの場合にはループが発生。
まとめ
Cognitive Service の アクションは 最近ではそれほど追加されなくなってしまったので、今のところ自分で HTTP アクションで API を呼び出す必要があります。
特に今回紹介した Computer Vision の Read API は日本語に対して非常に高い読み取り精度を持っているので、実運用でも使えるかなと思います。
アクションに比べて少し手間ではありますが、そこまで複雑ではないので、ぜひトライしてみてはいかがでしょうか。
ためしにレシートの画像で読み取ってみたいという場合にはこちらをどうぞ
https://raw.githubusercontent.com/mofumofu-dance/PowerApps365/master/misc/ocr_source.jpg
{kind=link}