
はじめに
名刺をアプリやフローで解析して連絡先に自動登録したい!
というような要望があったとします。 Power Platform なら AI Builder の 名刺リーダーがありますが、まだ日本語サポートされていなそうです。 Logic Apps でとなると、 Form recognizerを使うことになるかと思います。
Form recognizer は Logic Apps, Power Automateのどちらからも利用可能なコネクターが提供されていますが、利用しているAPIが v2.1で日本語非対応版なので、日本語の名刺をスキャンしても期待される結果を返してくれません。
実際日本語の名刺サンプル画像を使ってみると、本来名前や会社名、部署に含まれるべき日本語の情報が丸っと落とされていることがわかります。
{kind=link}
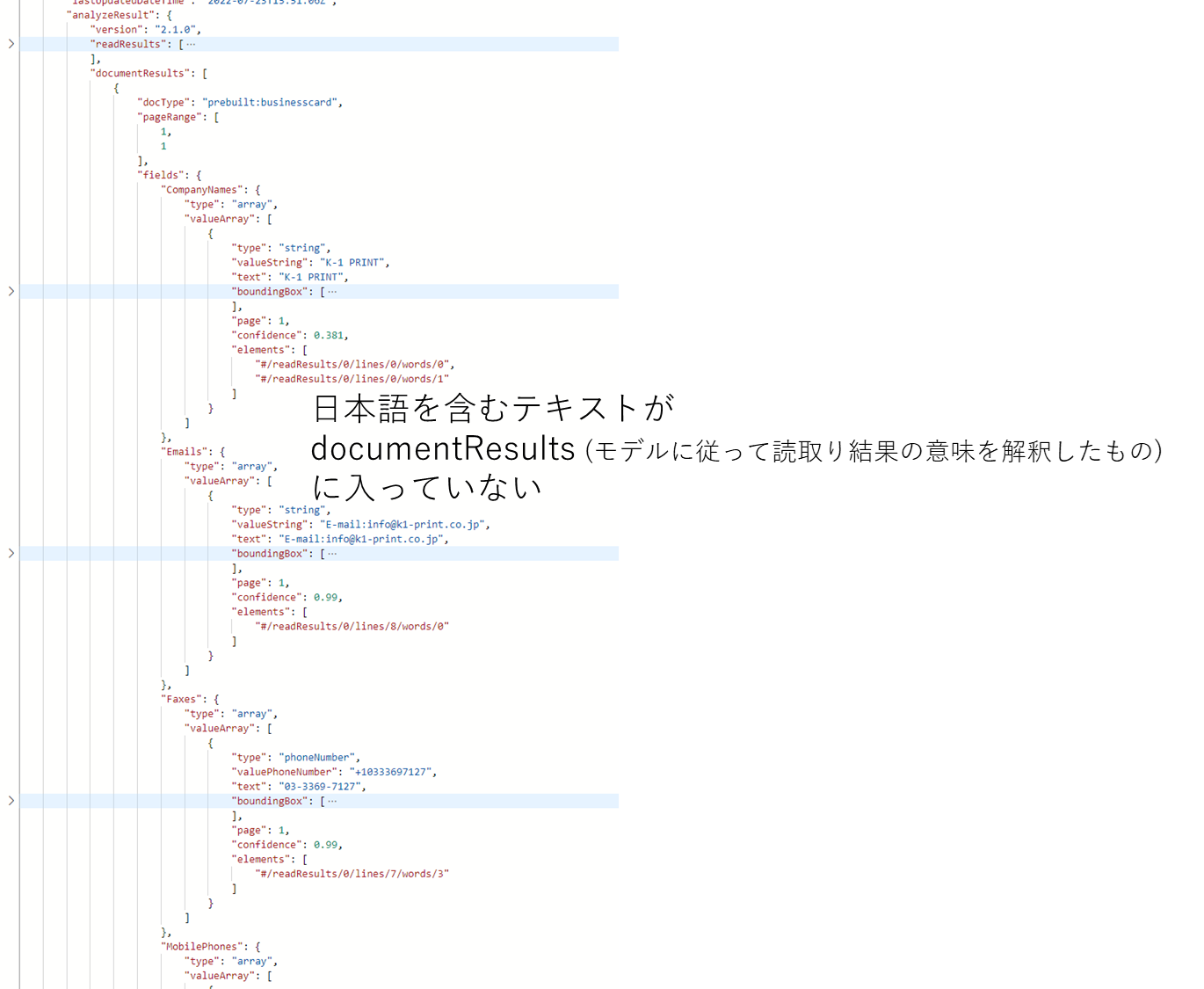
これはだいぶ残念仕様ですね。ということで、今回は 日本語対応した Form Recognizer v3.0 APIを Logic Apps/Power Automate で利用する場合の方法の例と、解析結果の考察をしていきます。
なお、Form recognizerのリソース作成などはここでは割愛します。公式のガイドを見ていただくのが間違いがないと思いますので以下からどうぞ。※APIのバージョンは v3.0を利用するとしても、リソース作成部分は変わりません。
Form Recognizer リソースを作成する方法 - Azure Applied AI Services | Microsoft Docs
フローの作成
フローで利用するAPIは以下の2つです。
解析要求
POST https://{Form recognizerのエンドポイントURL}/formrecognizer/documentModels/prebuilt-businessCard:analyze?api-version=2022-06-30-preview
解析結果取得
GET https://{Form recognizerのエンドポイントURL}/formrecognizer/documentModels/prebuilt-businessCard:analyze/AnalyzeResult/{resultId}?api-version=2022-06-30-preview
Ref: https://docs.microsoft.com/ja-jp/azure/applied-ai-services/form-recognizer/v3-migration-guide
最初の"解析要求"で、対象の名刺のURLまたはコンテンツを送信し、その後解析結果を"解析結果取得"でもらうという流れです。
注意しなければいけないのが、"解析結果取得"は即座にとれるわけではないということです。このため、フローの中ではDo untilのループを使って、結果が取れるまでグルグル回しています。
なお、"解析結果取得" 用のURLは、"解析要求" のレスポンスヘッダーに含まれる "Operation-Location" から得ることができますので、フローでもヘッダーの値を使っています。
フローの詳細
フロー全体は以下のように構成されています。
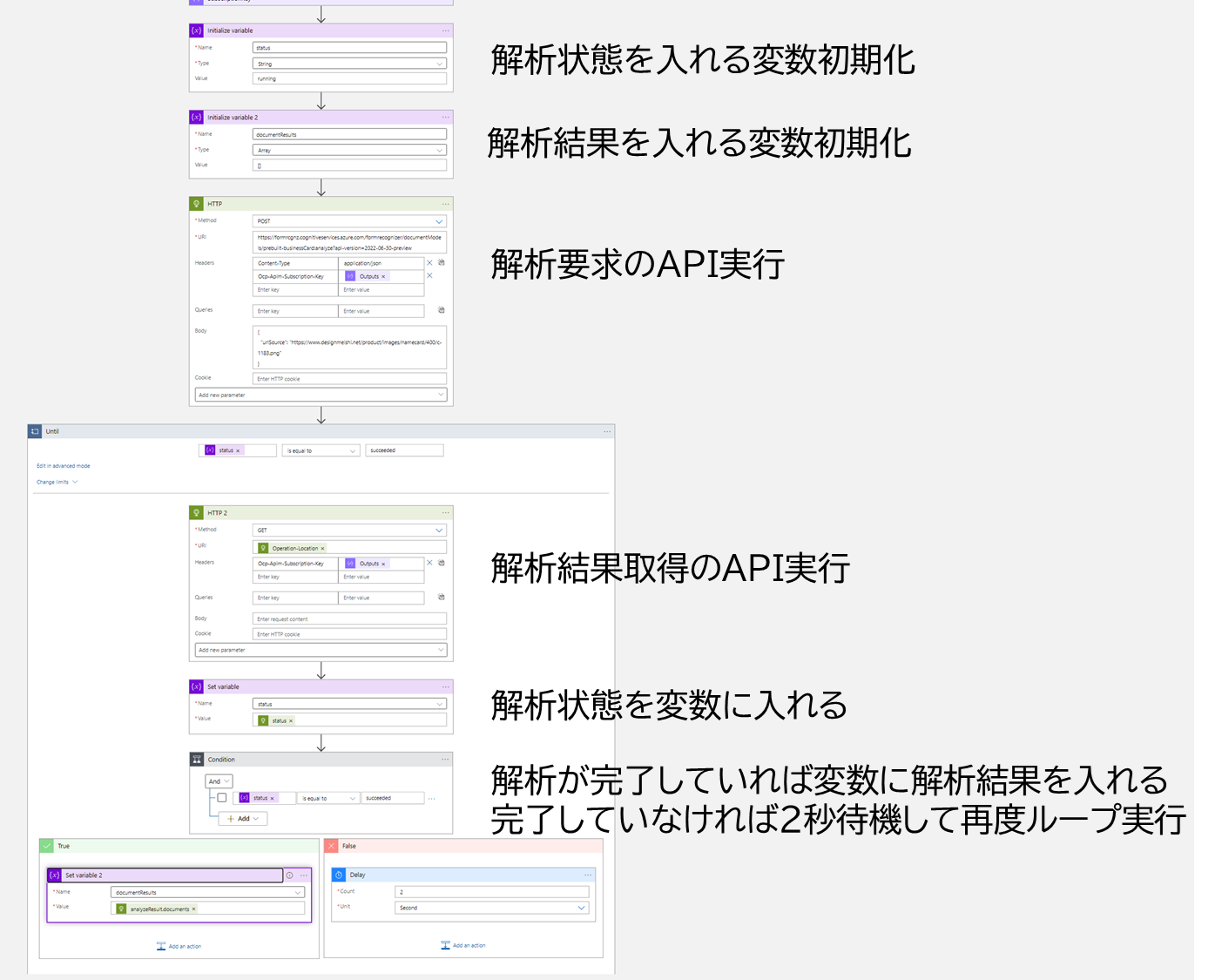
それぞれブロックごとに見ていきましょう。
変数初期化
特に解説ポイントはないです。 "status", "documentResults" という変数をそれぞれ文字列、アレイ型で初期化しています。

解析要求
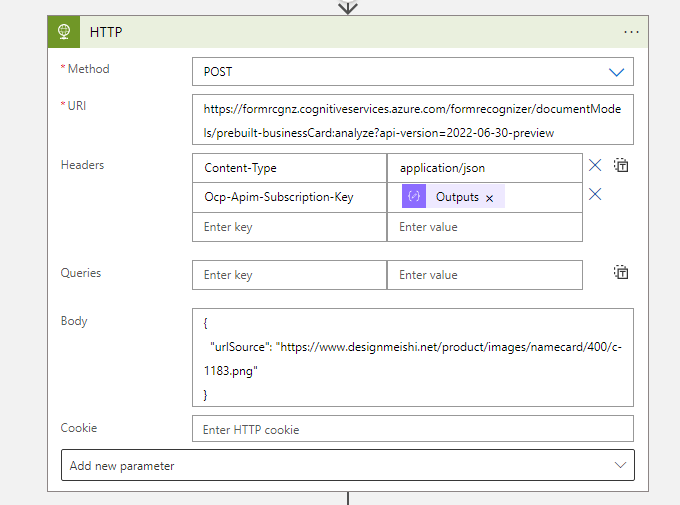
ここで1つ目のAPIを実行しています。 メソッドは POST で、 URIはご自身の作成したForm recognizerのリソースに合わせてください。
ヘッダーには Content-Type のほかに Ocp-Apim-Subscription-Key を設定します。ここはAPIキーです。(スクショでは隠すためにComposeの結果を使ってます)
ボディは、ここでは画像のURLを指定しています。 {"urlSource":"画像URL"} となるように設定してください。
ループ
解析結果取得は即時とれるわけではないので、Do Until (または Until) のループを使います。
ループの終了条件は最初に初期化した変数 "status" が 解析完了の "succeeded"になった時としています。
ループの最初に"解析結果取得" のAPIを実行しています。
URI は 最初のリクエスト (HTTPアクション) の結果を使っています。
outputs('HTTP')['headers']?['Operation-Location']
ヘッダーには最初のリクエストと同様、Ocp-Apim-Subscription-Keyを設定してください。

"解析結果取得"のAPIを実行したら、そこから得られる解析ステータス (まだ実行中なのか成功なのか)を "status" 変数にセットします。
body('HTTP_2')?['status']
あとは条件分岐で、”status"がsucceededだったら解析結果を変数にセットします。
body('HTTP_2')?['analyzeResult']?['documents']
ループ内はこのような感じになります。
実行結果
このフローを実行して "documentResults" 変数の中身を見てみると以下のとおり、期待される日本語の要素が抽出されていることがわかります。
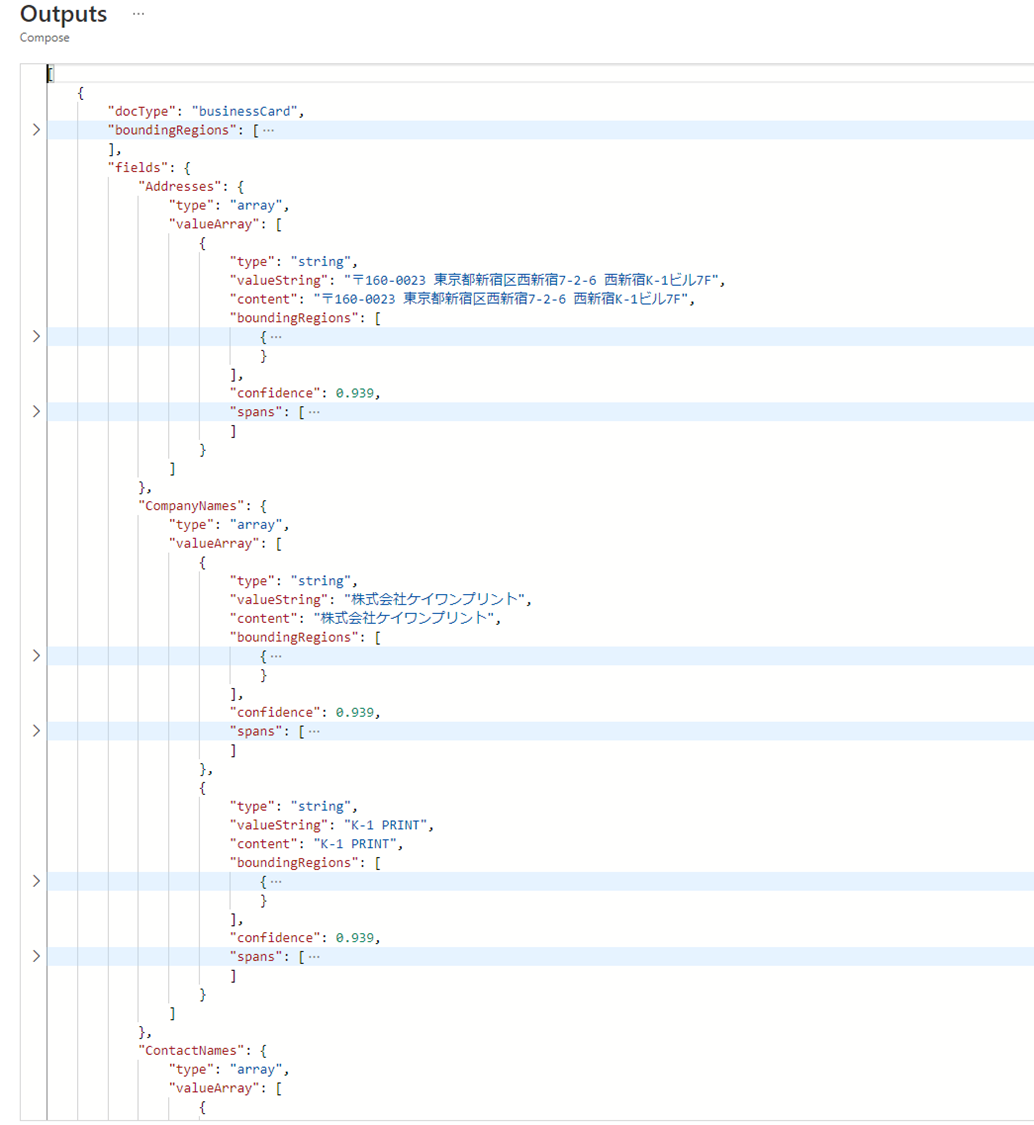
コネクターの結果と比べると一目瞭然ですね。特にロケールなど指定していませんが、日本語であることを読み取ってくれているようです。
結果の考察など
解析結果をみてまず気付くのは、各要素 (名前や住所、部署名など)が複数ある前提だということです。 (= 結果が配列型になっている)
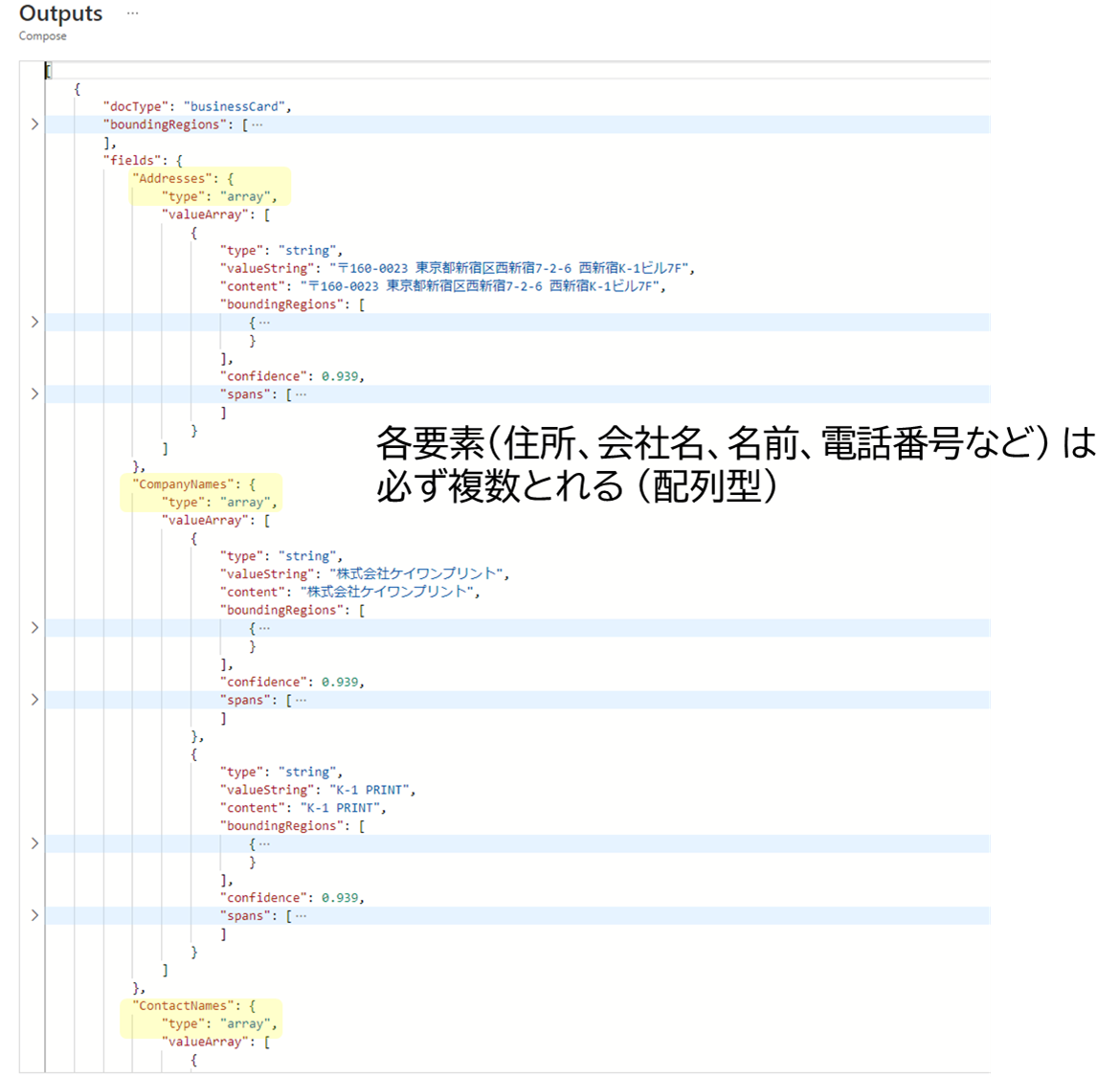
実際、名前が 漢字+ローマ字で併記される場合にはContactNamesに2つ行が入っていました。
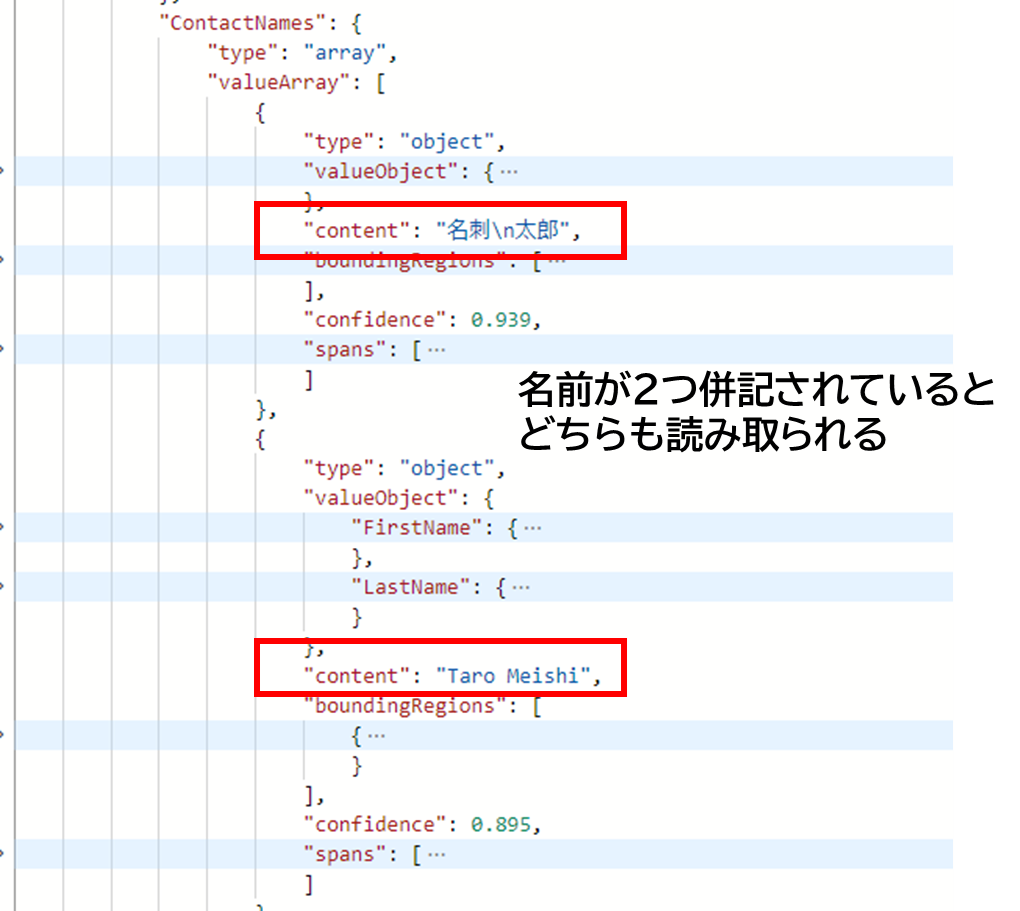
じゃあこれをどうしていくのか ですが、名刺のレイアウトが指定できないような状況では何らかの区切り文字で結合しておくのがいいのかなと思います。
名刺 太郎 | Taro Meishiのような形。
これを実現するためには、各要素について Select + Joinのアクションを組み合わせます。
例として名前 (ContactNames) の場合を見ていきます。

まず Select アクションのFrom に入れるのは
variables('documentResults')?[0]?['fields']?['ContactNames']?['valueArray']
です。1枚目の名刺 の 要素群 の ContactNames の 値を含む配列 を対象にしています。
Map の部分ですが、ここには
item()?['content']
を入れます。他の要素 (電話番号など) も観てみましたが、content を使うか、 valueStringを使うかちょっと微妙なところです。
最後のJoinアクションでは、Selectの結果を パイプ "|"で結合しています。
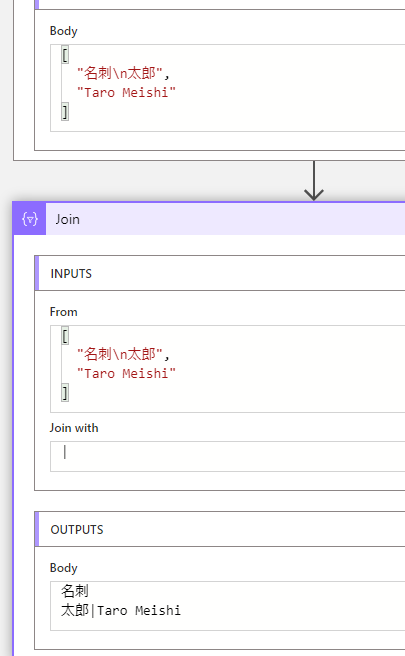
謎の改行は処理しておいたほうがいいですね。 replace(item()?['content'],decodeUriComponent('%0A'),'')という感じ
このように、複数とれる前提で結果が返ってくるので、無難に処理するにはSelect + Joinが必要になってきます。
おわり
Form Recognizer のコネクターがちょっといまいちだったので、今回はv3.0のAPIをHTTPアクションで実行してみました。
コネクターのバージョンが上がれば、ループ処理などは不要になりますが、結果の考察の部分は同じように処理しないといけなそうです。
やっぱりコネクター大事ですね。