はじめに
この投稿はPower Automate Advent Calendar 12/6 用に書いたものです。
Power Automateを使っていると、"JSONの解析"アクションは結構よく使います。 多くのケースでは、前段のアクションで得られるデータを動的コンテンツとして利用するためで、HTTP関連のアクションを使ってデータ取得した後に挿入されます。
この時、JSONを解析するために得られるデータの構造 - どういうプロパティがあるのか、データ型は何か等 - を指定する必要があります。これが JSON Schemaです。
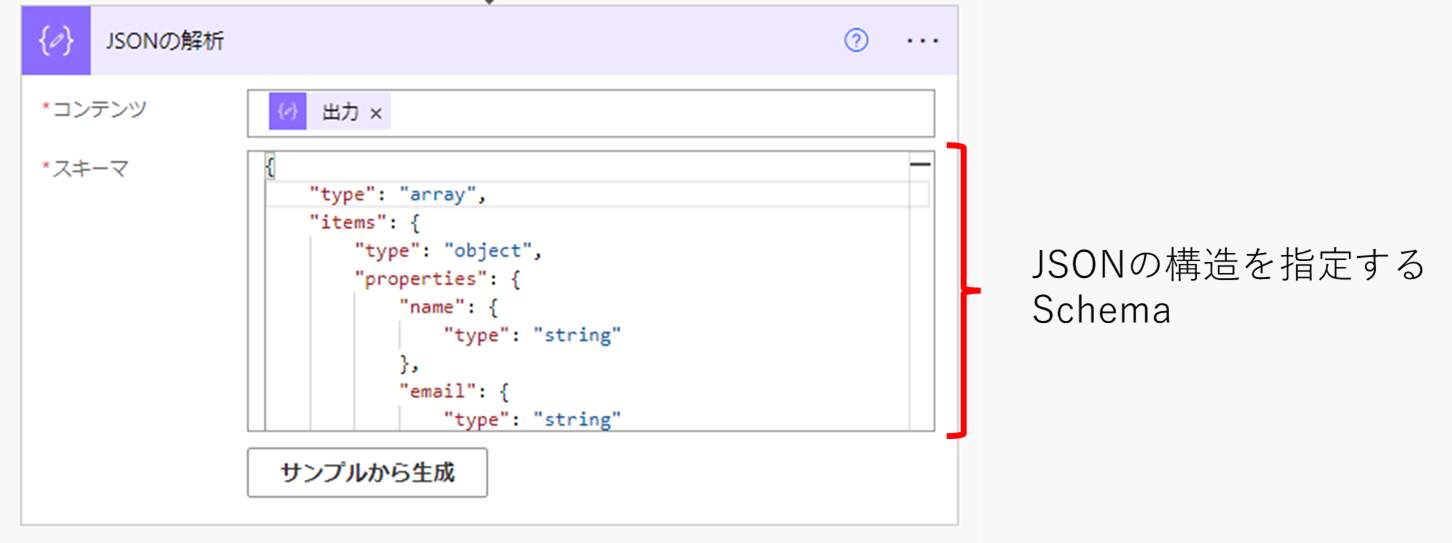
普段利用するときには、サンプルデータからスキーマを自動生成して使っていると思います。

今回は、この自動生成されたスキーマを基本にして、ちょっと応用した使い方を紹介していこうと思います。
なお、サンプルのJSONとしては以下の配列を利用します。
[ {"name":"Ram", "email":"ram@gmail.com", "age":23}, {"name":"Shyam", "email":"shyam23@gmail.com", "age":28}, {"name":"John", "email":"john@gmail.com", "age":33}, {"name":"Bob", "email":"bob32@gmail.com", "age":41} ]
自動生成されるスキーマは
{ "type": "array", "items": { "type": "object", "properties": { "name": { "type": "string" }, "email": { "type": "string" }, "age": { "type": "integer" } }, "required": [ "name", "email", "age" ] } }
表示名の上書きと説明の追加
一つ目のテクニックは動的コンテンツへの表示方法をカスタマイズするものです。
この方法はすでに太田さんが一部記載されています。
Power Automate の JSON の解析で値に名前を付けて分かりやすくする – idea.toString();
スキーマの中でtypeと併記して、titleやdescriptionを追加することで、動的コンテンツの表示を変更することができます。スキーマのうちname部分を以下のように書き換えてみます。
"name": {
"type": "string",
"title" : "名前",
"description":"これはユーザー名"
}
すると、動的コンテンツに表示される選択肢が以下のように変化します。
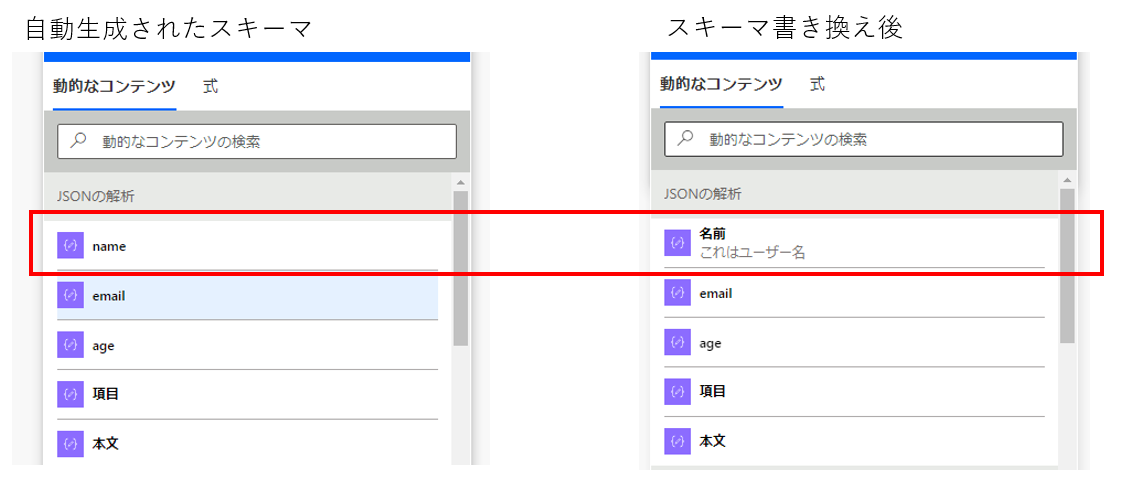
表示名がtitle部分で上書きされて、薄い文字で説明書きが追加されていることがわかるでしょう。
このテクニック、自分だけで使う分にはそれほど必要ないのかなと思いますが、複数人でフローをメンテナンスする可能性があるのであれば、「この値はこういう目的でとってますよ」というメモを残すことにもなります。可読性の向上目的で活用できるかと思います。
null のエラー回避
Power Automateがまだ Microsoft Flowだったころから親しまれたテクニックです。
一部のプロパティがnullになる場合、型が不一致でJSON解析がエラーになります。 (nullはそれはそれで一個のデータ型)
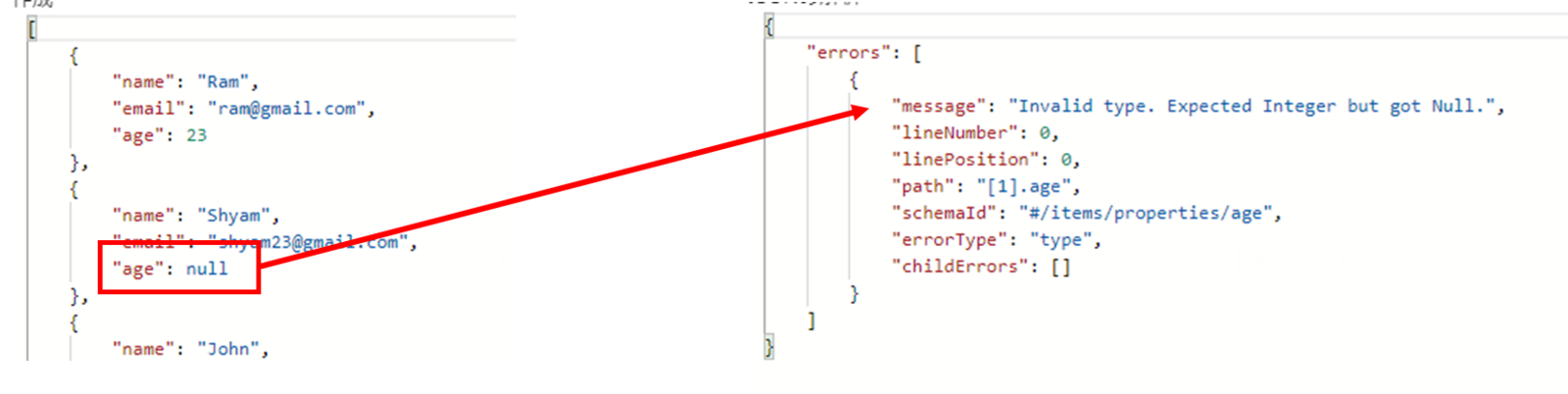
こんな時はスキーマ内のtypeを複数のデータ型に対応できるように書き換えます。
"age": { "type": ["integer","null"] }
本来は整数 (integer) が入りますが、nullでもエラーにならないように ["integer","null"] でどちらのデータ型も受け入れられるようにしています。
これでJSONの解析はエラーにならずに済みます。
データバリデーション
今回紹介するのはここが本番です。JSONの解析は単純に動的コンテンツに追加するだけでなく、解析対象となるJSONデータのバリデーションも行えるのです。
必須チェック
すでにサンプルのスキーマでも表れていますが、データに必ず含まれているべきプロパティがある場合には、requiredという属性を設定します。
"required": [ "name", "email", "age" ]
入ってきたデータにrequired に指定されたプロパティが含まれていないと解析アクションはエラーになります。これによって後続処理に回す前にデータの構造が期待するものか=データが揃っているかをチェックできます。
値の範囲
ある種の数値型/整数型データでは、値の取りうる範囲が決まっていたりします。年齢なら整数だとしても30000とかは入らないですよね。 そういうときに値の範囲を指定することが可能です。
"age": { "type": "integer", "minimum":25, "maximum":80 }
例えばageを25~80の範囲に限定したい場合には上記のようにminimumとmaximumを指定します。こうすると、入力データに25未満または81以上の値が含まれていると解析アクションがエラーになります。

また、文字列長での範囲指定もできます。
"email": { "type": "string", "minLength":20, "maxLength":100 }
email などは最大文字列があったりしますから、それを入れておくことで変なデータの混入を防げます。
文字列のフォーマット
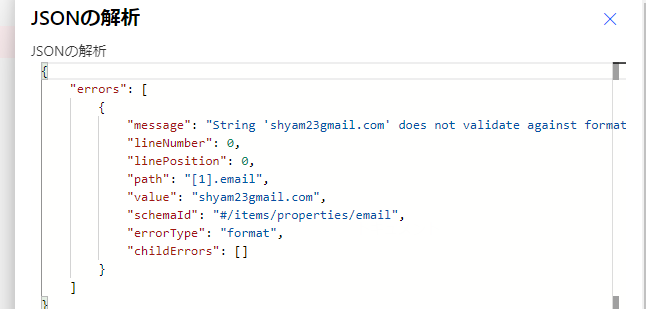
emailや日付などは文字列として扱われるわけですが、特定のフォーマットに従っている必要があります。 sample@contoso.comみたいに。 ここにhogehoge_contoso.comみたいな不正な文字列が入ってこないように、プリセットされた文字列フォーマットに当てはまるかチェックできます。
"email": { "type": "string", "format":"email" },
こんな風にformatを指定すれば、不正な文字列のデータが入ってきたときに解析アクションをエラーにすることができます。
他のフォーマットについては以下からどうぞ
string — Understanding JSON Schema 2020-12 documentation
使えないバリデーション
ここまで来て、「じゃあ正規表現も!?」と思われるかもしれません。しかし残念ながら正規表現でのバリデーションには対応していません。

おわり
今回はJSONの解析アクションのちょっと便利な使い方をご紹介しました。 特に、動的コンテンツへの説明文追加やデータのバリデーションは実際の業務システムと連携させるときに重要になるかと思います。
詳細は以下のJSON Schemaに関する辞書的なものを参考にしてみてください。